|
Georgia Institute of Technology

|

|
|
I am a fourth year Machine Learning PhD student at Georgia Tech advised by Prof. Zsolt Kira. My research interests lie at the intersection of computer vision and natural language processing.
|
|
|
|
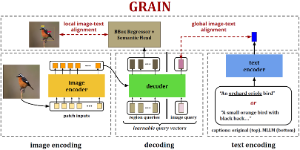
Shaunak Halbe, et. al. (hidden for anonymity) Under Review preprint(coming soon) VIRTUE unifies video search, composed retrieval, and moment localization in a single MLLM-based framework. |
|
Shaunak Halbe, Junjiao Tian, K J Joseph, James Smith, Katherine Stevo, Vineeth N Balasubramanian, Zsolt Kira Winter Conference on Applications of Computer Vision (WACV) 2026 preprint We propose a new VLM pretraining strategy to learn fine-grained representations that exhibit strong zero-shot transfer. |
|
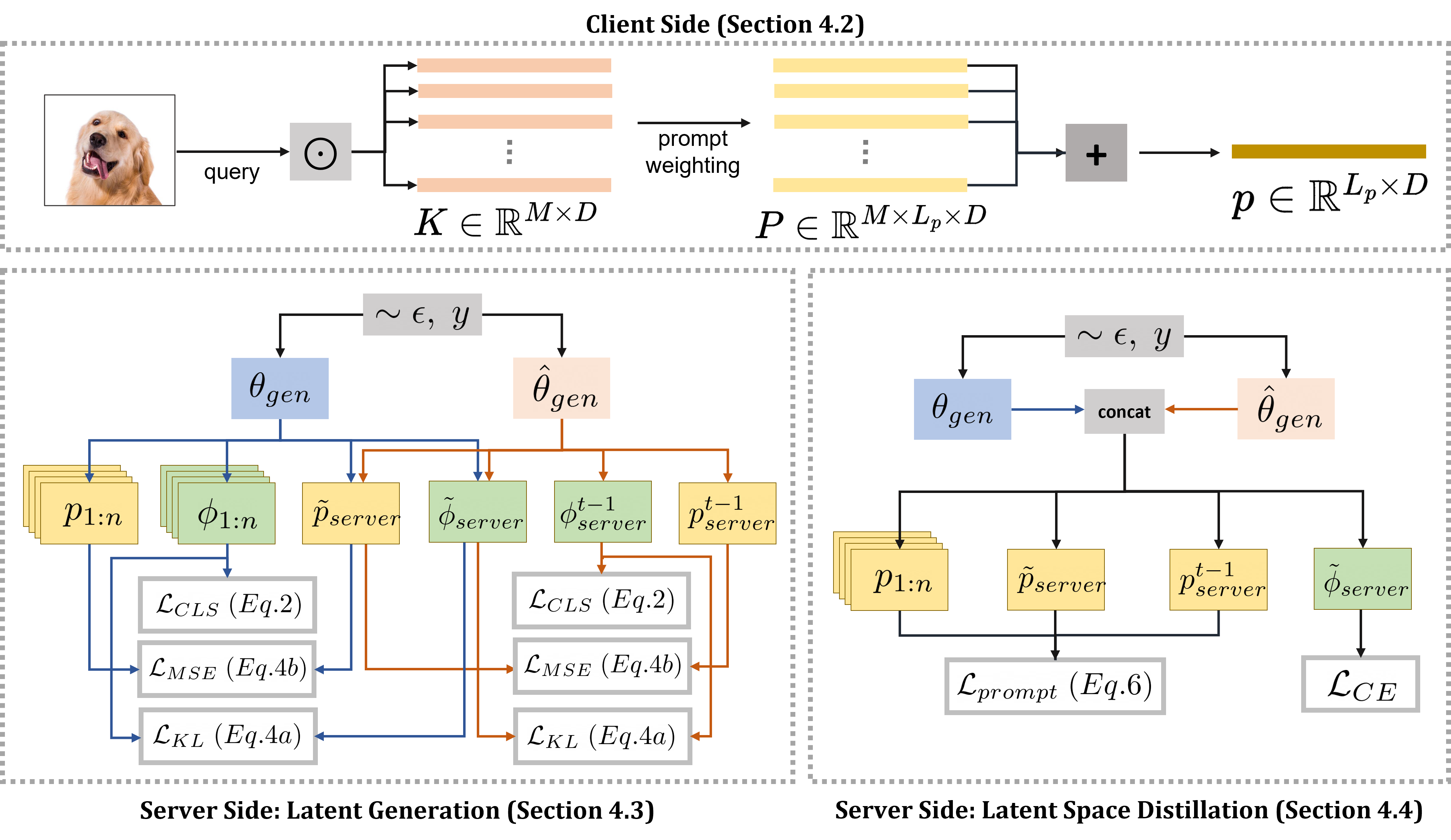
Shaunak Halbe, James Smith, Junjiao Tian, Zsolt Kira Transactions on Machine Learning Research (TMLR) 2024 Short Version: FL@FM Workshop, NeurIPS 2023 (Oral) paper / talk We propose a novel prompt learning and aggregation scheme for distributed training of foundation models. |

|
Tianjian Huang*, Shaunak Halbe*, Chinnadhurai Sankar, Pooyan Amini, Satwik Kottur, Alborz Geramifard, Meisam Razaviyayn, Ahmad Beirami Transactions on Machine Learning Research (TMLR) 2022 paper We introduce a novel loss-level regularizer to improve robustness in generative models. |
|
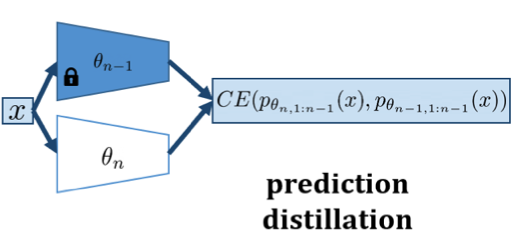
James Smith, Junjiao Tian, Shaunak Halbe, Yen-Chang Hsu, Zsolt Kira CVPR-W 2023 paper We introduce distillation and regularization baselines for continually training foundation models. |
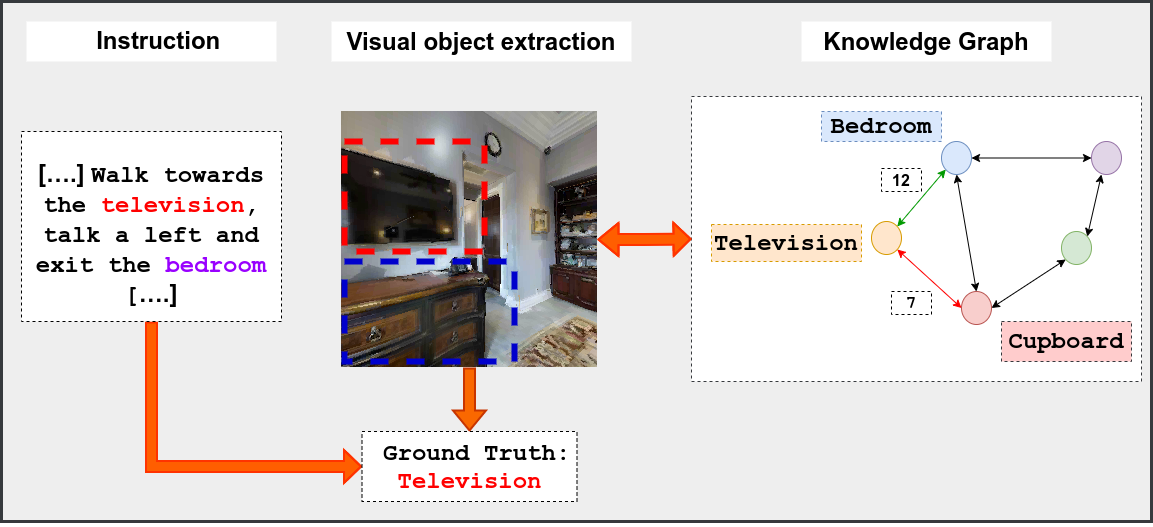
|
Shaunak Halbe, Ingrid Navarro, Jean Oh CMU Robotics Institute Working Papers Journal paper / poster / talk We present a modular agent for navigation with improved cross-modal grounding and semantic reasoning. |

|
Shaunak Halbe ACL-W 2020 Short Version: CVPR-W 2020 paper / talk We present a consistency analysis of VQA models through the lens of attribution to evaluate adversarial robustness. |
|
|
|
Website template cloned from here! |